
ResNet18
ResNet18是由何恺明等人于 2015 年提出的经典轻量级深度残差网络,核心是通过残差连接(Skip Connection)解决深层神经网络的退化问题(梯度消失 / 爆炸)。它结构简洁、计算高效,是计算机视觉领域最常用的基线模型之一
残差学习
传统网络直接学习原始特征映射H(x),ResNet改为学习残差映射F(x)=H(x)−x,输出H(x)=F(x)+x(输入直接加到后续层输出)
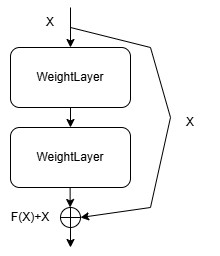
Lumos框架提供shortcut_layer帮助您实现残差结构,shortcut_layer提供两种模式如下
| 模式 | 描述 |
|---|---|
| 0 | 实现F(x)+x |
| 1 | 直接输出x |
代码构建示例如下
模式0
Layer *l1 = make_convolutional_layer(64, 3, 1, 1, 0, "relu");
Layer *l2 = make_convolutional_layer(64, 3, 1, 1, 0, "linear");
Layer *l3 = make_shortcut_layer(l1, 0, "relu");
模式1
Layer *l1 = make_convolutional_layer(128, 3, 2, 1, 0, "relu");
Layer *l2 = make_convolutional_layer(128, 3, 1, 1, 0, "linear");
Layer *l3 = make_shortcut_layer(l1, 1, "linear");
Layer *l4 = make_convolutional_layer(128, 1, 2, 0, 0, "linear");
Layer *l5 = make_shortcut_layer(l3, 0, "relu");
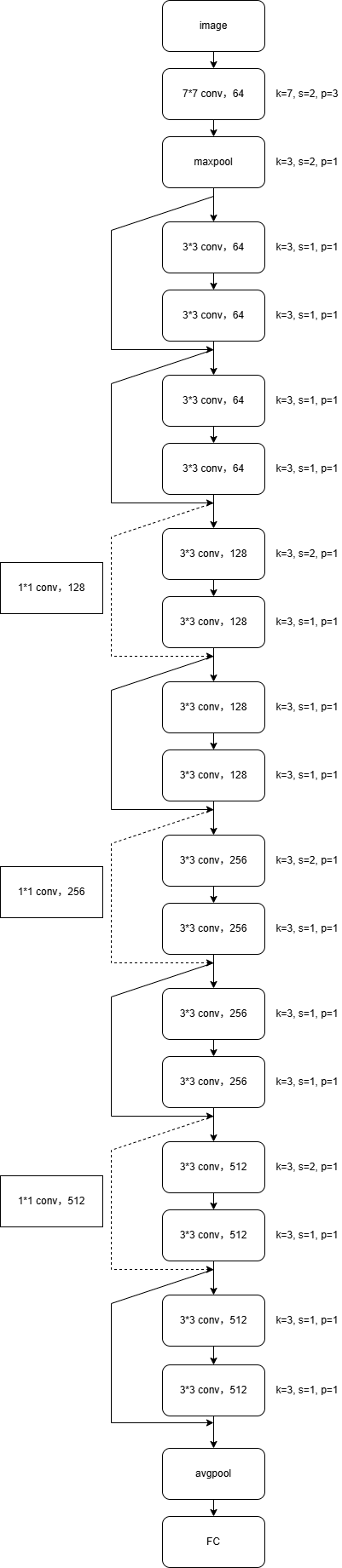
resnet18模型结构如下:
Flower数据集
我们提供的示例运用一个小型花卉数据集,我们在此不对数据集做过多介绍,您可以使用您的任意数据集在该模型上进行训练,我们的实例仅仅是展示在Lumos框架下构建模型的过程
代码构建
使用Lumos框架构建网络模型
Graph *g = create_graph();
Layer *l1 = make_convolutional_layer(64, 7, 2, 3, 0, "relu");
Layer *l2 = make_maxpool_layer(3, 2, 1);
Layer *l3 = make_convolutional_layer(64, 3, 1, 1, 0, "relu");
Layer *l4 = make_convolutional_layer(64, 3, 1, 1, 0, "linear");
Layer *l5 = make_shortcut_layer(l3, 0, "relu");
Layer *l6 = make_convolutional_layer(64, 3, 1, 1, 0, "relu");
Layer *l7 = make_convolutional_layer(64, 3, 1, 1, 0, "linear");
Layer *l8 = make_shortcut_layer(l6, 0, "relu");
Layer *l9 = make_convolutional_layer(128, 3, 2, 1, 0, "relu");
Layer *l10 = make_convolutional_layer(128, 3, 1, 1, 0, "linear");
Layer *l11 = make_shortcut_layer(l9, 1, "linear");
Layer *l12 = make_convolutional_layer(128, 1, 2, 0, 0, "linear");
Layer *l13 = make_shortcut_layer(l11, 0, "relu");
Layer *l14 = make_convolutional_layer(128, 3, 1, 1, 0, "relu");
Layer *l15 = make_convolutional_layer(128, 3, 1, 1, 0, "linear");
Layer *l16 = make_shortcut_layer(l14, 0, "relu");
Layer *l17 = make_convolutional_layer(256, 3, 2, 1, 0, "relu");
Layer *l18 = make_convolutional_layer(256, 3, 1, 1, 0, "linear");
Layer *l19 = make_shortcut_layer(l17, 1, "linear");
Layer *l20 = make_convolutional_layer(256, 1, 2, 0, 0, "linear");
Layer *l21 = make_shortcut_layer(l19, 0, "relu");
Layer *l22 = make_convolutional_layer(256, 3, 1, 1, 0, "relu");
Layer *l23 = make_convolutional_layer(256, 3, 1, 1, 0, "linear");
Layer *l24 = make_shortcut_layer(l22, 0, "relu");
Layer *l25 = make_convolutional_layer(512, 3, 2, 1, 0, "relu");
Layer *l26 = make_convolutional_layer(512, 3, 1, 1, 0, "linear");
Layer *l27 = make_shortcut_layer(l25, 1, "linear");
Layer *l28 = make_convolutional_layer(512, 1, 2, 0, 0, "linear");
Layer *l29 = make_shortcut_layer(l27, 0, "relu");
Layer *l30 = make_convolutional_layer(512, 3, 1, 1, 0, "relu");
Layer *l31 = make_convolutional_layer(512, 3, 1, 1, 0, "linear");
Layer *l32 = make_shortcut_layer(l30, 0, "relu");
Layer *l33 = make_avgpool_layer(7, 1, 0);
Layer *l34 = make_connect_layer(5, 1, "linear");
Layer *l35 = make_crossentropy_layer(NULL, -1);
我们使用crossentropy分类器进行分类
接下来指定各计算层的参数初始化
init_kaiming_uniform_kernel(l1, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l3, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l4, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l6, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l7, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l9, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l10, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l12, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l14, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l15, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l17, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l18, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l20, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l22, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l23, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l25, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l26, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l28, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l30, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l31, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l34, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_bias(l34, "fan_in");
构建会话,并设置相关训练超参数
Session *sess = create_session(g, 224, 224, 3, 5, type, path);
float *mean = calloc(3, sizeof(float));
float *std = calloc(3, sizeof(float));
mean[0] = 0.485;
mean[1] = 0.456;
mean[2] = 0.406;
std[0] = 0.229;
std[1] = 0.224;
std[2] = 0.225;
transform_normalize_sess(sess, mean, std);
transform_resize_sess(sess, 224, 224);
set_train_params(sess, 50, 32, 32, 0.001);
SGDOptimizer_sess(sess, 0.9, 0, 0, 0, 0);
init_session(sess, "./data/flower/train.txt", "./data/flower/train_label.txt");
可以看到我们对数据集进行了一定的预处理操作,首先对数据集进行归一化,归一化的分布来自于ImageNet数据集的先验计算结果,后续我们对数据集进行缩放,使其符合网络模型输入
我们使用SGD参数优化器进行参数优化
完整代码如下
#include "resnet18.h"
void resnet18(char *type, char *path)
{
Graph *g = create_graph();
Layer *l1 = make_convolutional_layer(64, 7, 2, 3, 0, "relu");
Layer *l2 = make_maxpool_layer(3, 2, 1);
Layer *l3 = make_convolutional_layer(64, 3, 1, 1, 0, "relu");
Layer *l4 = make_convolutional_layer(64, 3, 1, 1, 0, "linear");
Layer *l5 = make_shortcut_layer(l3, 0, "relu");
Layer *l6 = make_convolutional_layer(64, 3, 1, 1, 0, "relu");
Layer *l7 = make_convolutional_layer(64, 3, 1, 1, 0, "linear");
Layer *l8 = make_shortcut_layer(l6, 0, "relu");
Layer *l9 = make_convolutional_layer(128, 3, 2, 1, 0, "relu");
Layer *l10 = make_convolutional_layer(128, 3, 1, 1, 0, "linear");
Layer *l11 = make_shortcut_layer(l9, 1, "linear");
Layer *l12 = make_convolutional_layer(128, 1, 2, 0, 0, "linear");
Layer *l13 = make_shortcut_layer(l11, 0, "relu");
Layer *l14 = make_convolutional_layer(128, 3, 1, 1, 0, "relu");
Layer *l15 = make_convolutional_layer(128, 3, 1, 1, 0, "linear");
Layer *l16 = make_shortcut_layer(l14, 0, "relu");
Layer *l17 = make_convolutional_layer(256, 3, 2, 1, 0, "relu");
Layer *l18 = make_convolutional_layer(256, 3, 1, 1, 0, "linear");
Layer *l19 = make_shortcut_layer(l17, 1, "linear");
Layer *l20 = make_convolutional_layer(256, 1, 2, 0, 0, "linear");
Layer *l21 = make_shortcut_layer(l19, 0, "relu");
Layer *l22 = make_convolutional_layer(256, 3, 1, 1, 0, "relu");
Layer *l23 = make_convolutional_layer(256, 3, 1, 1, 0, "linear");
Layer *l24 = make_shortcut_layer(l22, 0, "relu");
Layer *l25 = make_convolutional_layer(512, 3, 2, 1, 0, "relu");
Layer *l26 = make_convolutional_layer(512, 3, 1, 1, 0, "linear");
Layer *l27 = make_shortcut_layer(l25, 1, "linear");
Layer *l28 = make_convolutional_layer(512, 1, 2, 0, 0, "linear");
Layer *l29 = make_shortcut_layer(l27, 0, "relu");
Layer *l30 = make_convolutional_layer(512, 3, 1, 1, 0, "relu");
Layer *l31 = make_convolutional_layer(512, 3, 1, 1, 0, "linear");
Layer *l32 = make_shortcut_layer(l30, 0, "relu");
Layer *l33 = make_avgpool_layer(7, 1, 0);
Layer *l34 = make_connect_layer(5, 1, "linear");
Layer *l35 = make_crossentropy_layer(NULL, -1);
append_layer2grpah(g, l1);
append_layer2grpah(g, l2);
append_layer2grpah(g, l3);
append_layer2grpah(g, l4);
append_layer2grpah(g, l5);
append_layer2grpah(g, l6);
append_layer2grpah(g, l7);
append_layer2grpah(g, l8);
append_layer2grpah(g, l9);
append_layer2grpah(g, l10);
append_layer2grpah(g, l11);
append_layer2grpah(g, l12);
append_layer2grpah(g, l13);
append_layer2grpah(g, l14);
append_layer2grpah(g, l15);
append_layer2grpah(g, l16);
append_layer2grpah(g, l17);
append_layer2grpah(g, l18);
append_layer2grpah(g, l19);
append_layer2grpah(g, l20);
append_layer2grpah(g, l21);
append_layer2grpah(g, l22);
append_layer2grpah(g, l23);
append_layer2grpah(g, l24);
append_layer2grpah(g, l25);
append_layer2grpah(g, l26);
append_layer2grpah(g, l27);
append_layer2grpah(g, l28);
append_layer2grpah(g, l29);
append_layer2grpah(g, l30);
append_layer2grpah(g, l31);
append_layer2grpah(g, l32);
append_layer2grpah(g, l33);
append_layer2grpah(g, l34);
append_layer2grpah(g, l35);
init_kaiming_uniform_kernel(l1, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l3, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l4, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l6, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l7, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l9, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l10, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l12, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l14, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l15, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l17, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l18, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l20, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l22, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l23, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l25, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l26, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l28, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l30, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l31, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_kernel(l34, sqrt(5.0), "fan_in", "leaky");
init_kaiming_uniform_bias(l34, "fan_in");
Session *sess = create_session(g, 224, 224, 3, 5, type, path);
float *mean = calloc(3, sizeof(float));
float *std = calloc(3, sizeof(float));
mean[0] = 0.485;
mean[1] = 0.456;
mean[2] = 0.406;
std[0] = 0.229;
std[1] = 0.224;
std[2] = 0.225;
transform_normalize_sess(sess, mean, std);
transform_resize_sess(sess, 224, 224);
set_train_params(sess, 50, 32, 32, 0.001);
SGDOptimizer_sess(sess, 0.9, 0, 0, 0, 0);
init_session(sess, "./data/flower/train.txt", "./data/flower/train_label.txt");
train(sess);
}
void resnet18_detect(char*type, char *path)
{
Graph *g = create_graph();
Layer *l1 = make_convolutional_layer(64, 7, 2, 3, 0, "relu");
Layer *l2 = make_maxpool_layer(3, 2, 1);
Layer *l3 = make_convolutional_layer(64, 3, 1, 1, 0, "relu");
Layer *l4 = make_convolutional_layer(64, 3, 1, 1, 0, "linear");
Layer *l5 = make_shortcut_layer(l3, 0, "relu");
Layer *l6 = make_convolutional_layer(64, 3, 1, 1, 0, "relu");
Layer *l7 = make_convolutional_layer(64, 3, 1, 1, 0, "linear");
Layer *l8 = make_shortcut_layer(l6, 0, "relu");
Layer *l9 = make_convolutional_layer(128, 3, 2, 1, 0, "relu");
Layer *l10 = make_convolutional_layer(128, 3, 1, 1, 0, "linear");
Layer *l11 = make_shortcut_layer(l9, 1, "linear");
Layer *l12 = make_convolutional_layer(128, 1, 2, 0, 0, "linear");
Layer *l13 = make_shortcut_layer(l11, 0, "relu");
Layer *l14 = make_convolutional_layer(128, 3, 1, 1, 0, "relu");
Layer *l15 = make_convolutional_layer(128, 3, 1, 1, 0, "linear");
Layer *l16 = make_shortcut_layer(l14, 0, "relu");
Layer *l17 = make_convolutional_layer(256, 3, 2, 1, 0, "relu");
Layer *l18 = make_convolutional_layer(256, 3, 1, 1, 0, "linear");
Layer *l19 = make_shortcut_layer(l17, 1, "linear");
Layer *l20 = make_convolutional_layer(256, 1, 2, 0, 0, "linear");
Layer *l21 = make_shortcut_layer(l19, 0, "relu");
Layer *l22 = make_convolutional_layer(256, 3, 1, 1, 0, "relu");
Layer *l23 = make_convolutional_layer(256, 3, 1, 1, 0, "linear");
Layer *l24 = make_shortcut_layer(l22, 0, "relu");
Layer *l25 = make_convolutional_layer(512, 3, 2, 1, 0, "relu");
Layer *l26 = make_convolutional_layer(512, 3, 1, 1, 0, "linear");
Layer *l27 = make_shortcut_layer(l25, 1, "linear");
Layer *l28 = make_convolutional_layer(512, 1, 2, 0, 0, "linear");
Layer *l29 = make_shortcut_layer(l27, 0, "relu");
Layer *l30 = make_convolutional_layer(512, 3, 1, 1, 0, "relu");
Layer *l31 = make_convolutional_layer(512, 3, 1, 1, 0, "linear");
Layer *l32 = make_shortcut_layer(l30, 0, "relu");
Layer *l33 = make_avgpool_layer(7, 1, 0);
Layer *l34 = make_connect_layer(5, 1, "linear");
Layer *l35 = make_crossentropy_layer(NULL, -1);
append_layer2grpah(g, l1);
append_layer2grpah(g, l2);
append_layer2grpah(g, l3);
append_layer2grpah(g, l4);
append_layer2grpah(g, l5);
append_layer2grpah(g, l6);
append_layer2grpah(g, l7);
append_layer2grpah(g, l8);
append_layer2grpah(g, l9);
append_layer2grpah(g, l10);
append_layer2grpah(g, l11);
append_layer2grpah(g, l12);
append_layer2grpah(g, l13);
append_layer2grpah(g, l14);
append_layer2grpah(g, l15);
append_layer2grpah(g, l16);
append_layer2grpah(g, l17);
append_layer2grpah(g, l18);
append_layer2grpah(g, l19);
append_layer2grpah(g, l20);
append_layer2grpah(g, l21);
append_layer2grpah(g, l22);
append_layer2grpah(g, l23);
append_layer2grpah(g, l24);
append_layer2grpah(g, l25);
append_layer2grpah(g, l26);
append_layer2grpah(g, l27);
append_layer2grpah(g, l28);
append_layer2grpah(g, l29);
append_layer2grpah(g, l30);
append_layer2grpah(g, l31);
append_layer2grpah(g, l32);
append_layer2grpah(g, l33);
append_layer2grpah(g, l34);
append_layer2grpah(g, l35);
Session *sess = create_session(g, 224, 224, 3, 5, type, path);
float *mean = calloc(3, sizeof(float));
float *std = calloc(3, sizeof(float));
mean[0] = 0.485;
mean[1] = 0.456;
mean[2] = 0.406;
std[0] = 0.229;
std[1] = 0.224;
std[2] = 0.225;
transform_normalize_sess(sess, mean, std);
transform_resize_sess(sess, 224, 224);
set_detect_params(sess);
init_session(sess, "./data/flower/train.txt", "./data/flower/train_label.txt");
detect_classification(sess);
}
在Lumos框架中demo目录下,您能找到resnet18.c文件,这就是我们已实现的resnet18模型
结果展示
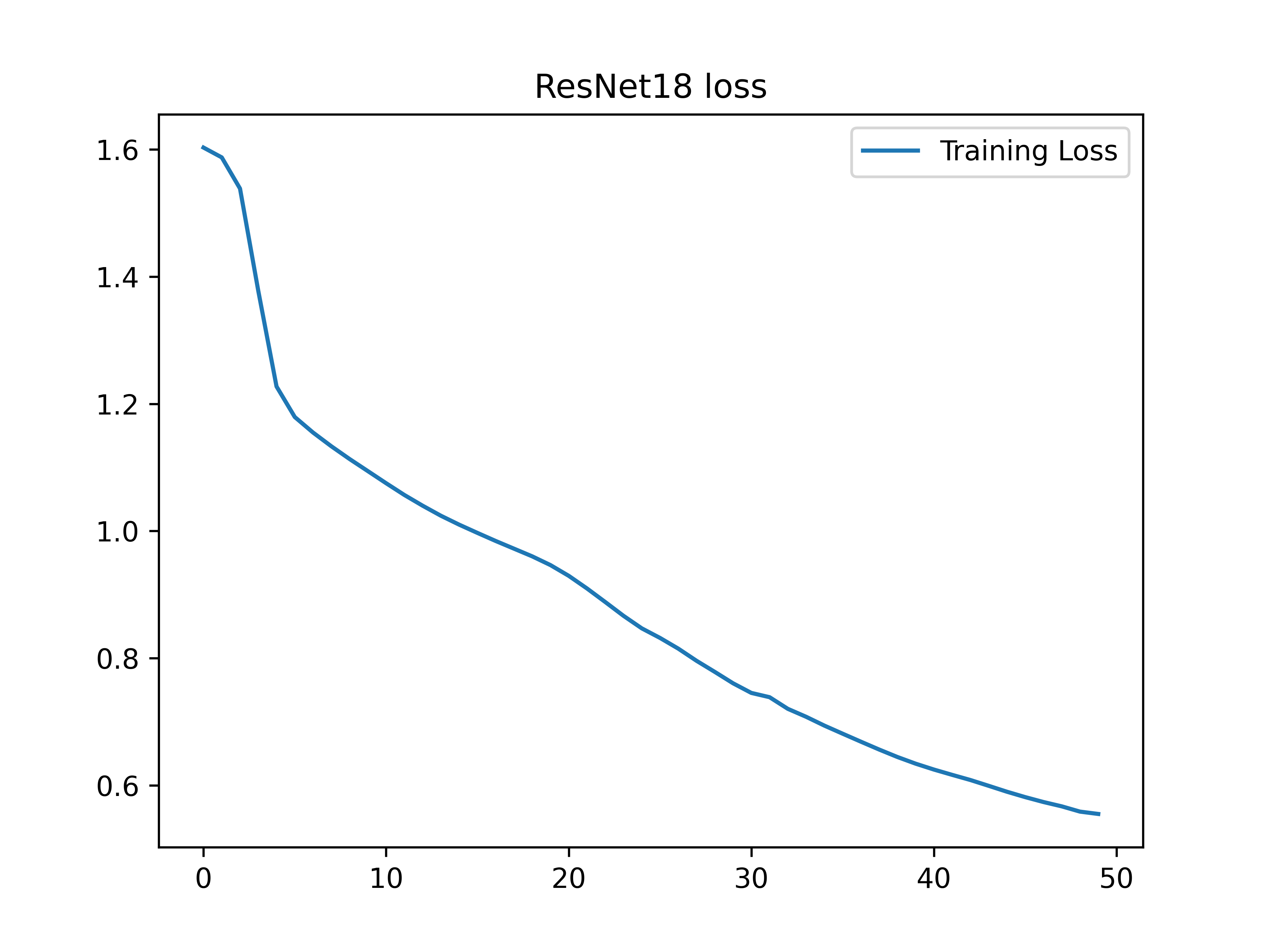
该网络在经过50个epoch训练后,分类精度在85%左右