
VGG16
VGG16 是牛津大学视觉几何组(VGG)在 2014 年 ILSVRC(ImageNet 竞赛)中提出的深度卷积神经网络,对应论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》,它证明了深度 + 统一小卷积核的设计远超当时的大卷积核方案,成为 CV 领域经典基础模型。
vgg16统一使用3×3卷积核(步长 1,padding=1,保持尺寸),参数更少、非线性更强;所有池化都是2×2 MaxPool,步长2,特征图尺寸减半;激活函数为ReLU,避免梯度消失;全连接层加入Dropout防止过拟合;训练采用小批量梯度下降、权重衰减(L2 正则)
优点:结构极简、统一,易实现、易迁移;预训练权重在多种 CV 任务(分类、检测、分割、特征提取)上效果稳定;
缺点:参数量巨大(约 138亿个),计算与内存开销高;深层梯度易退化;全连接层对输入尺寸敏感;
其网络结构如下:

cifar10数据集
CIFAR(Canadian Institute for Advanced Research)-10 由 Alex Krizhevsky、Vinod Nair、Geoffrey Hinton 于 2009 年发布,源自更大的 Tiny Images 数据集;是计算机视觉领域最经典、入门友好的图像分类基准数据集
官方地址:https://www.cs.toronto.edu/~kriz/cifar.html
共60,000张32×32RGB彩色图像;50,000 张训练集(分5个批次,每个批次10,000张),10,000 张测试集;10 个互斥类别,每类 6000 张(训练 5,000、测试 1,000)
| 编号 | 类别 | 编号 | 类别 |
|---|---|---|---|
| 0 | airplane(飞机) | 5 | dog(狗) |
| 1 | automobile(汽车) | 6 | frog(青蛙) |
| 2 | bird(鸟) | 7 | horse(马) |
| 3 | cat(猫) | 8 | ship(船) |
| 4 | deer(鹿) | 9 | truck(卡车) |

代码构建
使用Lumos框架构建网络模型
Graph *g = create_graph();
Layer *l1 = make_convolutional_layer(64, 3, 1, 1, 1, "relu");
Layer *l3 = make_convolutional_layer(64, 3, 1, 1, 1, "relu");
Layer *l5 = make_maxpool_layer(2, 2, 0);
Layer *l6 = make_convolutional_layer(128, 3, 1, 1, 1, "relu");
Layer *l8 = make_convolutional_layer(128, 3, 1, 1, 1, "relu");
Layer *l10 = make_maxpool_layer(2, 2, 0);
Layer *l11 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l13 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l15 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l17 = make_maxpool_layer(2, 2, 0);
Layer *l18 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l20 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l22 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l24 = make_maxpool_layer(2, 2, 0);
Layer *l25 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l27 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l29 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l31 = make_maxpool_layer(2, 2, 0);
Layer *l32 = make_dropout_layer(0.5);
Layer *l33 = make_connect_layer(4096, 1, "relu");
Layer *l34 = make_dropout_layer(0.5);
Layer *l35 = make_connect_layer(4096, 1, "relu");
Layer *l36 = make_connect_layer(10, 1, "linear");
Layer *l37 = make_crossentropy_layer(NULL, -1);
我们使用crossentropy分类器进行分类
接下来指定各计算层的参数初始化
init_kaiming_uniform_kernel(l1, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l3, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l6, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l8, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l11, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l13, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l15, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l18, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l20, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l22, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l25, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l27, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l29, sqrt(5.0), "fan_in", "relu");
init_kaiming_normal_kernel(l33, sqrt(5.0), "fan_in", "relu");
init_kaiming_normal_kernel(l35, sqrt(5.0), "fan_in", "relu");
init_kaiming_normal_kernel(l36, sqrt(5.0), "fan_in", "relu");
init_constant_bias(l1, 0);
init_constant_bias(l3, 0);
init_constant_bias(l6, 0);
init_constant_bias(l8, 0);
init_constant_bias(l11, 0);
init_constant_bias(l13, 0);
init_constant_bias(l15, 0);
init_constant_bias(l18, 0);
init_constant_bias(l20, 0);
init_constant_bias(l22, 0);
init_constant_bias(l25, 0);
init_constant_bias(l27, 0);
init_constant_bias(l29, 0);
init_constant_bias(l33, 0);
init_constant_bias(l35, 0);
init_constant_bias(l36, 0);
构建会话,并设置相关训练超参数
Session *sess = create_session(g, 32, 32, 3, 10, type, path);
float *mean = calloc(3, sizeof(float));
float *std = calloc(3, sizeof(float));
mean[0] = 0.5;
mean[1] = 0.5;
mean[2] = 0.5;
std[0] = 0.5;
std[1] = 0.5;
std[2] = 0.5;
transform_normalize_sess(sess, mean, std);
transform_resize_sess(sess, 32, 32);
set_train_params(sess, 40, 32, 32, 0.001);
SGDOptimizer_sess(sess, 0.9, 0, 0, 0, 0);
init_session(sess, "./data/cifar10/train.txt", "./data/cifar10/train_label.txt");
可以看到我们对数据集进行了一定的预处理操作,首先对数据集进行归一化,归一化的分布来自于ImageNet数据集的先验计算结果,后续我们对数据集进行缩放,使其符合网络模型输入
我们使用SGD参数优化器进行参数优化
完整代码如下
#include "vgg16_cifar10.h"
void vgg16_cifar10(char *type, char *path)
{
Graph *g = create_graph();
Layer *l1 = make_convolutional_layer(64, 3, 1, 1, 1, "relu");
Layer *l3 = make_convolutional_layer(64, 3, 1, 1, 1, "relu");
Layer *l5 = make_maxpool_layer(2, 2, 0);
Layer *l6 = make_convolutional_layer(128, 3, 1, 1, 1, "relu");
Layer *l8 = make_convolutional_layer(128, 3, 1, 1, 1, "relu");
Layer *l10 = make_maxpool_layer(2, 2, 0);
Layer *l11 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l13 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l15 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l17 = make_maxpool_layer(2, 2, 0);
Layer *l18 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l20 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l22 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l24 = make_maxpool_layer(2, 2, 0);
Layer *l25 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l27 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l29 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l31 = make_maxpool_layer(2, 2, 0);
Layer *l32 = make_dropout_layer(0.5);
Layer *l33 = make_connect_layer(4096, 1, "relu");
Layer *l34 = make_dropout_layer(0.5);
Layer *l35 = make_connect_layer(4096, 1, "relu");
Layer *l36 = make_connect_layer(10, 1, "linear");
Layer *l37 = make_crossentropy_layer(NULL, -1);
append_layer2grpah(g, l1);
append_layer2grpah(g, l3);
append_layer2grpah(g, l5);
append_layer2grpah(g, l6);
append_layer2grpah(g, l8);
append_layer2grpah(g, l10);
append_layer2grpah(g, l11);
append_layer2grpah(g, l13);
append_layer2grpah(g, l15);
append_layer2grpah(g, l17);
append_layer2grpah(g, l18);
append_layer2grpah(g, l20);
append_layer2grpah(g, l22);
append_layer2grpah(g, l24);
append_layer2grpah(g, l25);
append_layer2grpah(g, l27);
append_layer2grpah(g, l29);
append_layer2grpah(g, l31);
append_layer2grpah(g, l32);
append_layer2grpah(g, l33);
append_layer2grpah(g, l34);
append_layer2grpah(g, l35);
append_layer2grpah(g, l36);
append_layer2grpah(g, l37);
init_kaiming_uniform_kernel(l1, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l3, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l6, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l8, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l11, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l13, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l15, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l18, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l20, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l22, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l25, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l27, sqrt(5.0), "fan_in", "relu");
init_kaiming_uniform_kernel(l29, sqrt(5.0), "fan_in", "relu");
init_kaiming_normal_kernel(l33, sqrt(5.0), "fan_in", "relu");
init_kaiming_normal_kernel(l35, sqrt(5.0), "fan_in", "relu");
init_kaiming_normal_kernel(l36, sqrt(5.0), "fan_in", "relu");
init_constant_bias(l1, 0);
init_constant_bias(l3, 0);
init_constant_bias(l6, 0);
init_constant_bias(l8, 0);
init_constant_bias(l11, 0);
init_constant_bias(l13, 0);
init_constant_bias(l15, 0);
init_constant_bias(l18, 0);
init_constant_bias(l20, 0);
init_constant_bias(l22, 0);
init_constant_bias(l25, 0);
init_constant_bias(l27, 0);
init_constant_bias(l29, 0);
init_constant_bias(l33, 0);
init_constant_bias(l35, 0);
init_constant_bias(l36, 0);
Session *sess = create_session(g, 32, 32, 3, 10, type, path);
float *mean = calloc(3, sizeof(float));
float *std = calloc(3, sizeof(float));
mean[0] = 0.5;
mean[1] = 0.5;
mean[2] = 0.5;
std[0] = 0.5;
std[1] = 0.5;
std[2] = 0.5;
transform_normalize_sess(sess, mean, std);
transform_resize_sess(sess, 32, 32);
set_train_params(sess, 40, 32, 32, 0.001);
SGDOptimizer_sess(sess, 0.9, 0, 0, 0, 0);
init_session(sess, "./data/cifar10/train.txt", "./data/cifar10/train_label.txt");
train(sess);
}
void vgg16_cifar10_detect(char *type, char *path)
{
Graph *g = create_graph();
Layer *l1 = make_convolutional_layer(64, 3, 1, 1, 1, "relu");
Layer *l3 = make_convolutional_layer(64, 3, 1, 1, 1, "relu");
Layer *l5 = make_maxpool_layer(2, 2, 0);
Layer *l6 = make_convolutional_layer(128, 3, 1, 1, 1, "relu");
Layer *l8 = make_convolutional_layer(128, 3, 1, 1, 1, "relu");
Layer *l10 = make_maxpool_layer(2, 2, 0);
Layer *l11 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l13 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l15 = make_convolutional_layer(256, 3, 1, 1, 1, "relu");
Layer *l17 = make_maxpool_layer(2, 2, 0);
Layer *l18 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l20 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l22 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l24 = make_maxpool_layer(2, 2, 0);
Layer *l25 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l27 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l29 = make_convolutional_layer(512, 3, 1, 1, 1, "relu");
Layer *l31 = make_maxpool_layer(2, 2, 0);
Layer *l32 = make_dropout_layer(0.5);
Layer *l33 = make_connect_layer(4096, 1, "relu");
Layer *l34 = make_dropout_layer(0.5);
Layer *l35 = make_connect_layer(4096, 1, "relu");
Layer *l36 = make_connect_layer(10, 1, "linear");
Layer *l37 = make_crossentropy_layer(NULL, -1);
append_layer2grpah(g, l1);
append_layer2grpah(g, l3);
append_layer2grpah(g, l5);
append_layer2grpah(g, l6);
append_layer2grpah(g, l8);
append_layer2grpah(g, l10);
append_layer2grpah(g, l11);
append_layer2grpah(g, l13);
append_layer2grpah(g, l15);
append_layer2grpah(g, l17);
append_layer2grpah(g, l18);
append_layer2grpah(g, l20);
append_layer2grpah(g, l22);
append_layer2grpah(g, l24);
append_layer2grpah(g, l25);
append_layer2grpah(g, l27);
append_layer2grpah(g, l29);
append_layer2grpah(g, l31);
append_layer2grpah(g, l32);
append_layer2grpah(g, l33);
append_layer2grpah(g, l34);
append_layer2grpah(g, l35);
append_layer2grpah(g, l36);
append_layer2grpah(g, l37);
Session *sess = create_session(g, 32, 32, 3, 10, type, path);
float *mean = calloc(3, sizeof(float));
float *std = calloc(3, sizeof(float));
mean[0] = 0.5;
mean[1] = 0.5;
mean[2] = 0.5;
std[0] = 0.5;
std[1] = 0.5;
std[2] = 0.5;
transform_normalize_sess(sess, mean, std);
transform_resize_sess(sess, 32, 32);
set_detect_params(sess);
init_session(sess, "./data/cifar10/train.txt", "./data/cifar10/train_label.txt");
detect_classification(sess);
}
在Lumos框架中demo目录下,您能找到vgg16_cifar10.c文件,这就是我们已实现的vgg16模型
结果展示
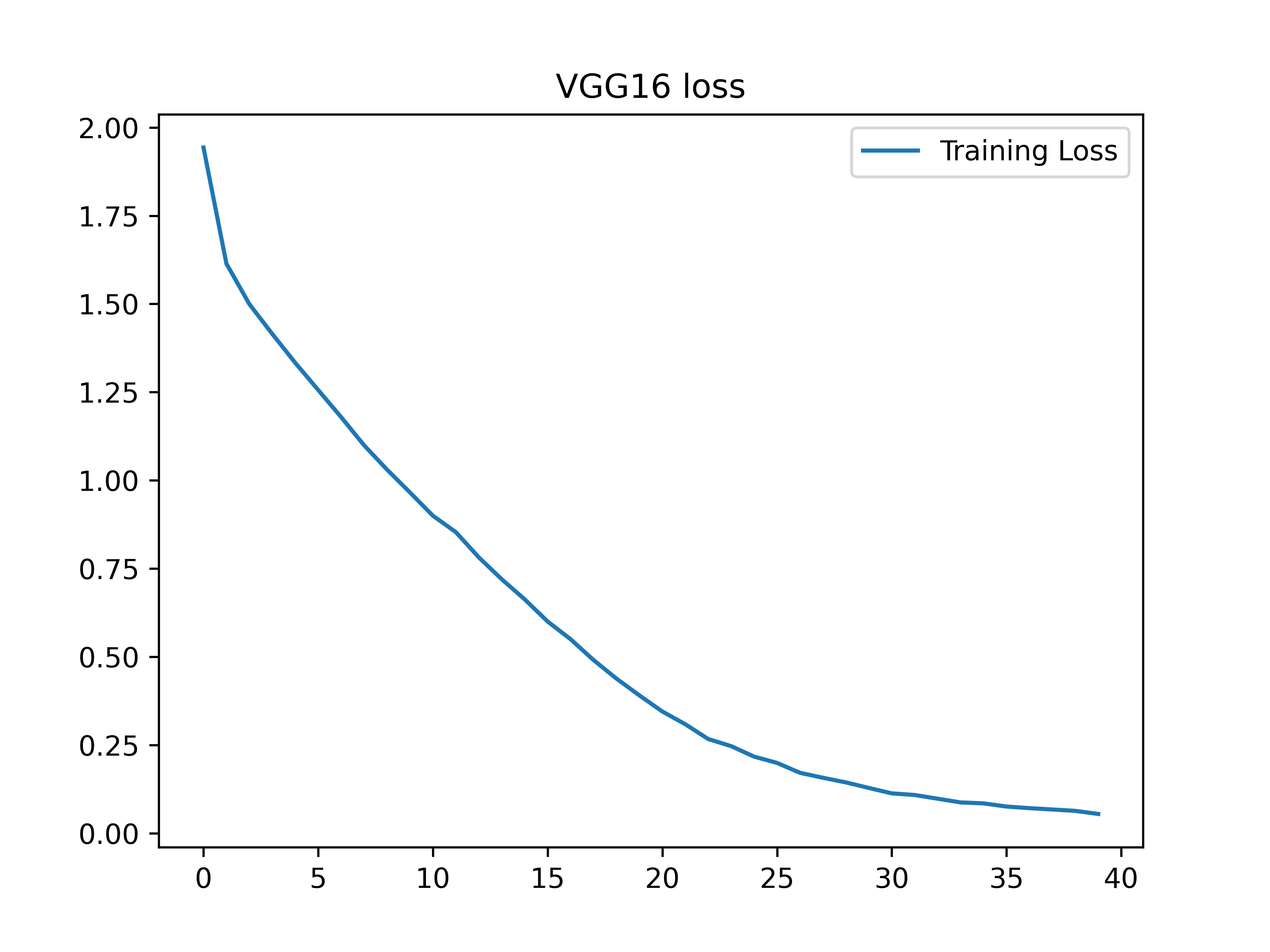
该网络在经过40个epoch训练后,分类精度在95%左右